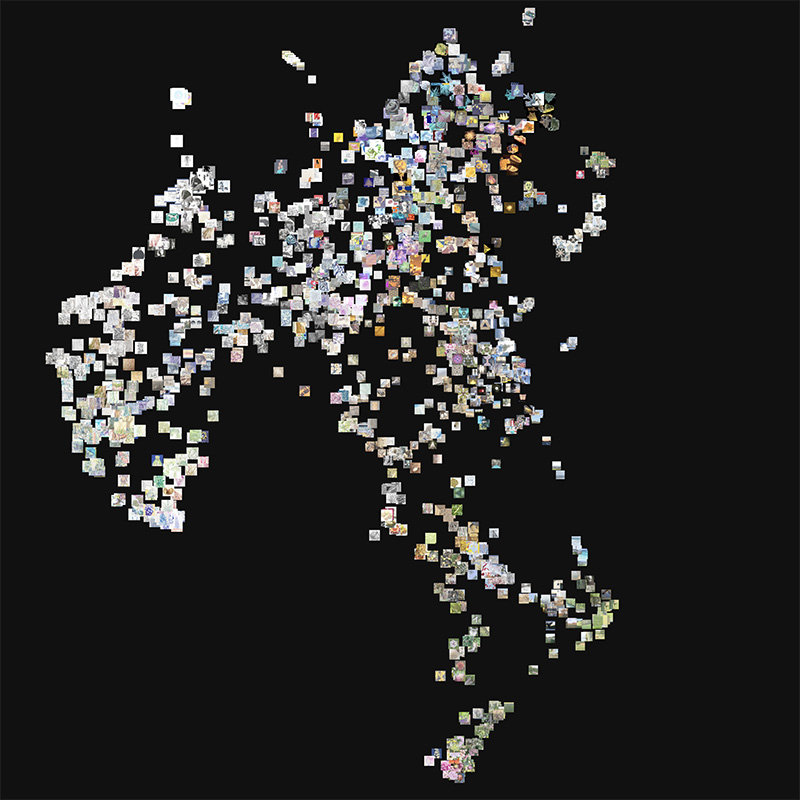Für visuelle Botschaften,
die ankommen.
EXPERIMENTS
Clustering my Instagram posts based on visual similarity and semantics

How I made it (in a few hours with a little bit of help from Anthropic's Claude ;-)

running a Python script to compute the CLIP embeddings
1. Loading OpenAI's CLIP model (Contrastive Language-Image Pre-training). CLIP is a multimodal AI model that correlates visual concepts with natural language. 400 million image-text pairs were used to extract the link between the visual structure of an image and its semantics.
2. Encoding the JPEG images; computing the CLIP embeddings
3. The reduction of the 512 dimensions to 3D is done using UMAP (Uniform Manifold Approximation and Projection) – a fancy way to project high-dimensional vectors using stochastic gradient descent. I admit that I don'd know the nitty-gritty but it seems to work well and preserves the topology even in three-dimensional space.

writing the 3d vectors to a .json file
3. Writing the 3d coordinates for each image into a json file that can be parsed by the the WebGL-based app. Each record contains the name/URL of the image and its 3d coordinate – the position of the image in space.

parsing the .json file and rendering the images in space using WebGL
4. A WebGL-based web app running in the browser parses the .json file and computes the overall bounding box of the loaded images. The camera's point of interest is set accordingly and renders a 3d scene using sprites. The textured sprites have an animated rollover state and repositions the camera's point of interest gradually when double-clicking. This behaviour simplifies the navigation.
> launch the web app
Projects